WorkLog: Optimizing Convolution
Convolution is a fundamental mathematical operation used extensively in signal processing, image processing and deep learning(particularly in Convolutional Neural Networks).
- GPU Used: RTX 3060
- Code is available at: Convolution in CUDA
Mathematical Definition
Continuous-time Convolution
For two functions f(t) and g(t):
where,
- f(t) : input signal
- g(t): impulse response/ kernel/ filter
- (f * g)(t): convolution of f and g, i.e. the output signal
Discrete-time Convolution
where,
- x[n]: input discrete signal
- h[n]: impulse response / kernel
- y[n]: output signal
- h[n - k]:
- index reversal
- shift by n
In this post, I benchmark CUDA implementations of convolution and analyze their performance across 1D, 2D, and 3D convolution workloads.
1D Convolution
Constraints
- 1 ≤ input_size ≤ 1,500,000
- 1 ≤ kernel_size ≤ 2047
- kernel_size ≤ input_size
Benchmarking
cuDNN
- Setup/ Description Phase
/* cuDNN setup */
cudnnHandle_t cudnn; // Declare cuDNN execution context required for all cuDNN operations
CUDNN_CHECK(cudnnCreate(&cudnn));
cudnnTensorDescriptor_t xDesc, yDesc; // Declares tensor descriptors in cuDNN. Do not store data - only describe how it is laid out in memory
cudnnFilterDescriptor_t filterDesc;
cudnnConvolutionDescriptor_t convDesc;
CUDNN_CHECK(cudnnCreateTensorDescriptor(&xDesc));
CUDNN_CHECK(cudnnCreateTensorDescriptor(&yDesc));
CUDNN_CHECK(cudnnCreateFilterDescriptor(&filterDesc));
CUDNN_CHECK(cudnnCreateConvolutionDescriptor(&convDesc));
At this stage:
- No computation happens
- No memory is touched
Only telling cuDNN:
- What tensors, filters & convolution look like.
- Which GPU/stream to use.
- Configuration Phase
// Set tensor and filter descriptors
CUDNN_CHECK(cudnnSetTensor4dDescriptor(xDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, 1, N, 1));
CUDNN_CHECK(cudnnSetTensor4dDescriptor(yDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, 1, outSize, 1));
CUDNN_CHECK(cudnnSetFilter4dDescriptor(filterDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, 1, 1, K, 1));
// Set convolution descriptor
CUDNN_CHECK(cudnnSetConvolution2dDescriptor(convDesc,
0, 0, // pad height, width
1, 1, // vertical, horizontal stride
1, 1, // dilation height, width
CUDNN_CROSS_CORRELATION,
CUDNN_DATA_FLOAT));
Mode: CUDNN_CROSS_CORRELATION
- Standard convolution operation as used in DL
- No kernel flip
Compute Type: CUDNN_DATA_FLOAT
- Precision: 32-bit floating point(FP32)
- Execution Phase
cudnnConvolutionFwdAlgoPerf_t perf;
int returnedAlgoCount = 0;
CUDNN_CHECK(cudnnGetConvolutionForwardAlgorithm_v7(
cudnn,
xDesc,
filterDesc,
convDesc,
yDesc,
1, // max number of algorithms to return
&returnedAlgoCount,
&perf
));
cudnnConvolutionFwdAlgo_t algo = perf.algo;
// Workspace
size_t workspaceSize = perf.memory;
void* d_workspace = nullptr;
if(workspaceSize > 0){
CUDA_CHECK(cudaMalloc(&d_workspace, workspaceSize));
}
- cudnnConvolutionFwdAlgoPerf_t
- struct contains everything cuDNN learned about one algorithm:
| Field | Meaning |
|---|---|
| algo | Which algorithm was chosen |
| time | Estimated execution time (ms) |
| memory | Workspace size required |
| status | Whether this algo is valid |
| mathType | Tensor Core / default math |
- cudnnConvolutionFwdAlgo_t algo = perf.algo; -> locking in cuDNN’s best guess. For our case, cuDNN uses CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PPRECOMP_GEMM
Actual Execution point
CUDNN_CHECK(cudnnConvolutionForward(
cudnn,
&alpha,
xDesc,
d_input,
filterDesc,
d_filter,
convDesc,
algo,
d_workspace,
workspaceSize,
&beta,
yDesc,
d_output
));
Custom CUDA Kernels
Naive method
__global__ void convolution_1d_kernel(const float* input, const float* kernel, float* output,
int input_size, int kernel_size) {
int tid = threadIdx.x + blockDim.x * blockIdx.x;
if(tid + kernel_size < input_size + 1){
float temp = 0.0f;
for(int i = 0;i < kernel_size;i++){
temp += input[tid + i] * kernel[i];
}
output[tid] = temp;
}
}
Using shared memory
__global__ void convolution_1d_kernel_shared_mem(const float* input, const float* kernel, float* output,
int input_size, int kernel_size) {
extern __shared__ float sI[];
int tid = threadIdx.x;
int base = blockDim.x * blockIdx.x;
for(int i = tid; i < blockDim.x + kernel_size - 1; i+=blockDim.x){
sI[i] = (base + i < input_size) ? input[base + i] : 0.0f;
}
__syncthreads();
int gid = base + tid;
if(gid < input_size - kernel_size + 1){
float temp = 0.0f;
#pragma unroll
for(int i = 0;i < kernel_size;i++){
temp += kernel[i] * sI[tid + i];
}
output[gid] = temp;
}
}
The same benchmarking methodology is extended to 2D and 3D convolutions, enabling a consistent comparison across dimensions.
Constraints for 2D Convolution
- 1 ≤ input_rows, input_cols ≤ 3072
- 1 ≤ kernel_rows, kernel_cols ≤ 31
- kernel_rows ≤ input_rows
- kernel_cols ≤ input_cols
Constraints for 3D Convolution
- 1 ≤ input_depth, input_rows, input_cols ≤ 256
- 1 ≤ kernel_depth, kernel_rows, kernel_cols ≤ 5
- kernel_depth ≤ input_depth
- kernel_rows ≤ input_rows
- kernel_cols ≤ input_cols
Results
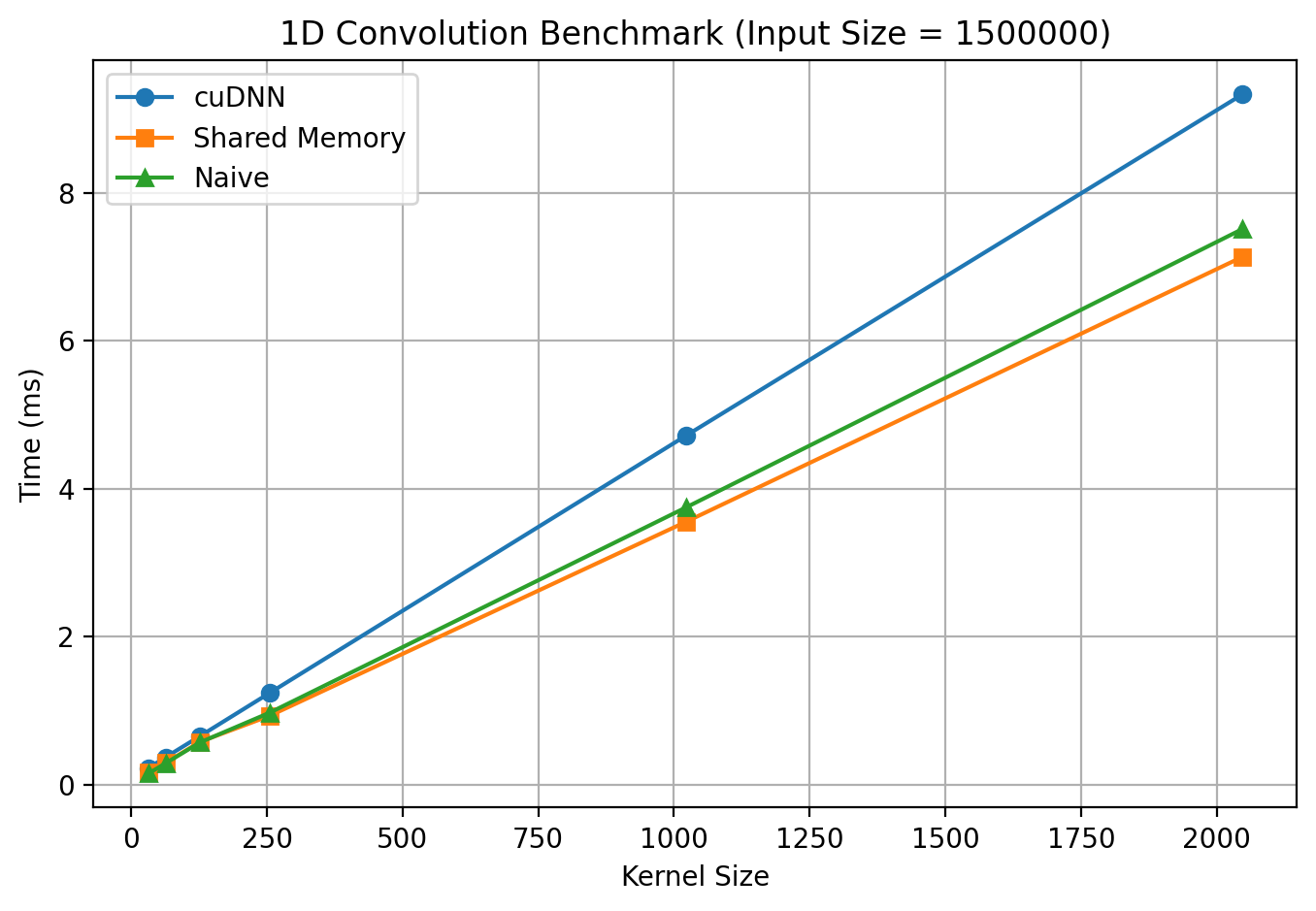
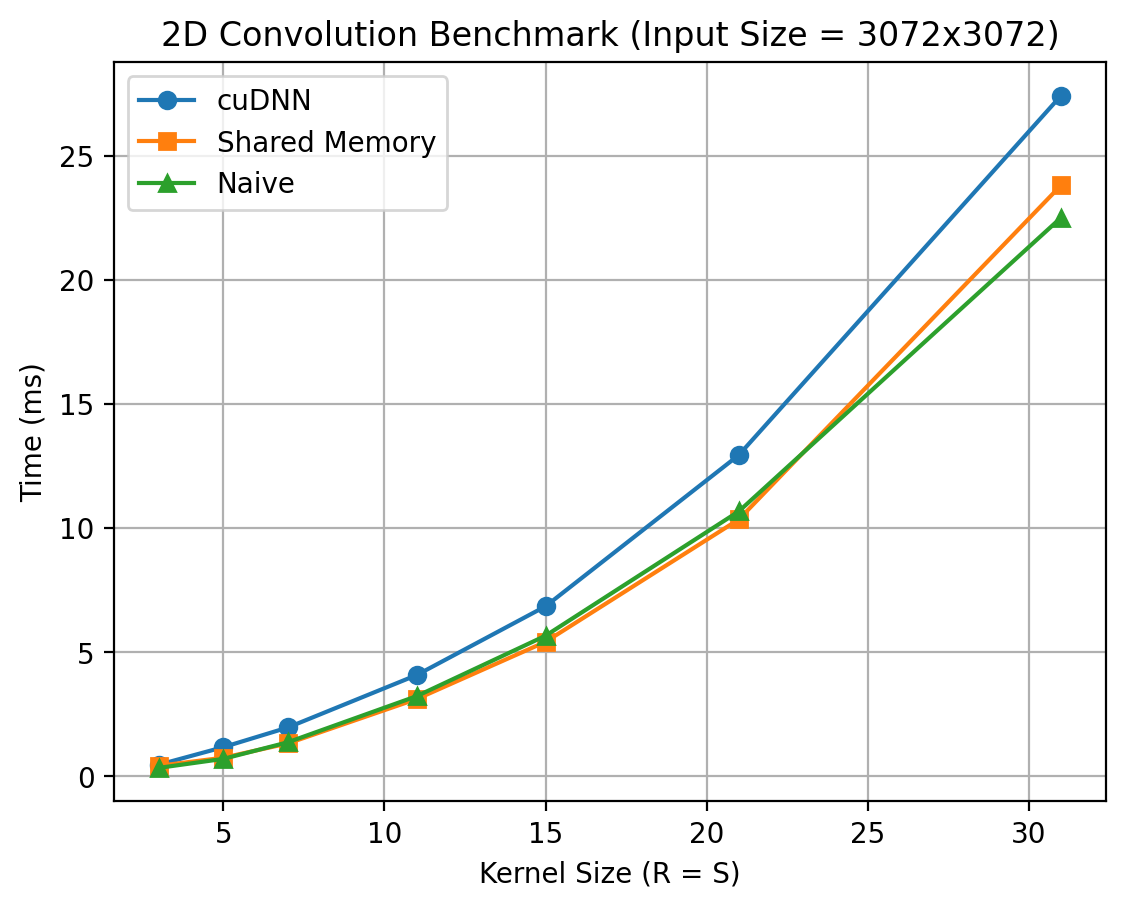
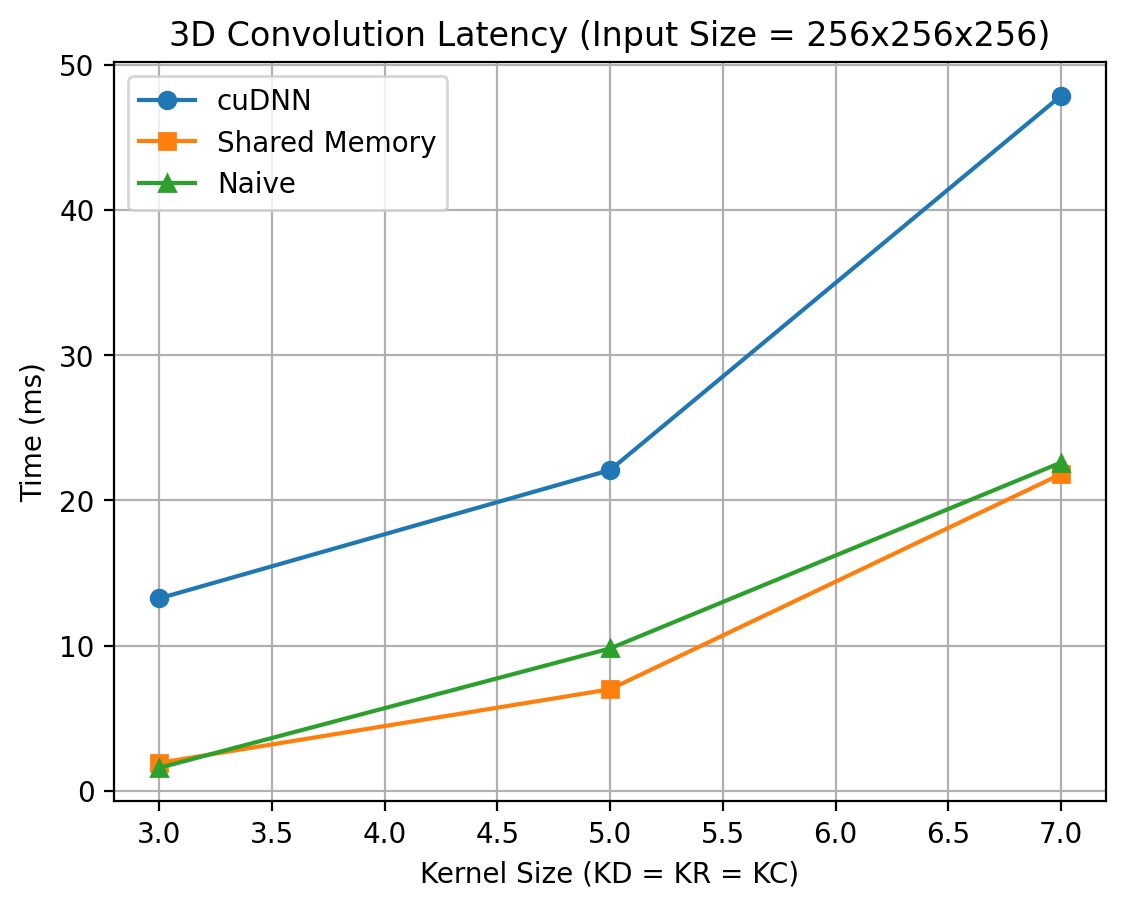
Comments on the above results
- Why cuDNN results are not what I was expecting?
- cuDNN is optimized for:
- Large batch sizes
- Multiple channels(C > 1)
- End-to-end throughput, not single-call latency
- In out benchmark, out setup is
- Batch = 1
- Channels = 1
- Single convolution per measurement
- Kernel size sweep(algorithm re-selection every time)
- Worst-case scenario for cuDNN
- cuDNN is optimized for:
Future Exploration
Future work will involve profiling with NVIDIA Nsight Systems and NVIDIA Nsight Compute to break down execution time into kernel launches, memory stalls, and compute utilization, providing deeper insight into why cuDNN underperforms compared to custom kernels in low-channel convolution settings.