WorkLog: Optimizing Softmax Kernel
From ChatGPT to image generation, one of the key operations these applications rely on is one important mathematical function: softmax. Neural Networks produce raw, unbounded numbers- called logits.
- However most tasks require probabilities, e.g. What class is this? What token comes next?
Softmax is the mathematical bridge to this. It transforms the unstructured scores into a stable probability distribution function that are easy to optimize with cross-entropy loss.
In this worklog, I am going to optimize the softmax kernel and benchmark against Pytorch’s softmax operation.
- GPU used: RTX 3060
- Code is available at Github: Optimizing SoftMax in CUDA
- Reduction blog: blog link
Background
Mathematical formula:
where,
- z is the vector of logits
- is the i-th element in the vector z
- exponential of the i-th element of the logits
- probability assigned to the i-th class after applying the softmax transformation
Note: If the values of zᵢ is too large(or too small), then the exponential might cause overflow(or underfloat) depending on the precision limits of the modern computer. So for extreme cases, the above softmax version is not numerically stable. To prevent potential overflow(or underflow) issues, will be using the max trick. So the formula becomes
For the purpose of this exercise, will be using a 1D array of size N.
Theoretical Performance Limit
Bytes loaded: Load the whole vector once and save it once, so we get 2 times our vector size memory accesses of floating-point values that are 4 bytes each.
For the FLOPs, we have to split our function into suboperations
This leaves us with 5 FLOPs per 8 bytes loaded.
Max memory bandwidth, (5/8) * 336 GB/s = 210 GFLOPs
So softmax is essentially a memory-bound operation
Benchmark
cuDNN Kernel
- cuDNN: CUDA Deep Neural Network Library
- NVIDIA's highly optimized GPU library for deep-learning primitives
1. Create a cuDNN handle
One of the first things while working with cuDNN is to create a cuDNN handle, which cuDNN uses to manage resources, state, and execution settings for all cuDNN operations. cuDNN functions cannot run without a handle.
// Initializes cuDNN and associates with the current CUDA context.
cudnnHandle_t cudnn;
cudnnCreate(&cudnn);
cudnnSetTensor4dDescriptor(
tensorDesc,
CUDNN_TENSOR_NCHW,
CUDNN_DATA_FLOAT,
1, size, 1, 1);
2. Create a tensor descriptor and describe the tensor layout
cuDNN does not infer tensor shape, layout or data type from pointers. So, we use tensor descriptor to tell cuDNN how to interpret the memory.
cudnnTensorDescriptor_t tensorDesc;
cudnnCreateTensorDescriptor(&tensorDesc);
3. Run softmax
cuDNN defines softmax over the C(channel) dimension by design. So when we want softmax over a vector, we pack the vector over channel C. output = alpha * softmax(input) + beta * output
float alpha = 1.0f;
float beta = 0.0f;
cudnnSoftmaxForward(
cudnn,
CUDNN_SOFTMAX_ACCURATE,
CUDNN_SOFTMAX_MODE_CHANNEL,
&alpha,
tensorDesc,
d_input,
&beta,
tensorDesc,
d_output);
- CUDNN_SOFTMAX_MODE_CHANNEL means softmax is applied across C
- With N=1, H=1, W=1, this is equivalent to a softmax over a vector of length size
Pytorch
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
y = torch.softmax(x, dim=1)
end.record()
torch.cuda.synchronize()
CUDA Kernel 1: Naive method
Our first approach is to do max reduction, sum reduction all in a same kernel.
Computing softmax of one array = one collective operation = one block.
blocksPerGrid = 1
shared memory size = 2 * threadsPerBlock * sizeof(float)
- Only one kernel launch
__global__ void softmax_naive(const float *input, float *output, int N){
extern __shared__ float sdata[];
float* max_vals = sdata;
float* sum_vals = &sdata[blockDim.x];
int tid = threadIdx.x;
// Find max value in row
float thread_max = -FLT_MAX;
for(int i = tid; i < N; i += blockDim.x){
thread_max = fmaxf(thread_max, input[i]);
}
max_vals[tid] = thread_max;
__syncthreads();
// Parallel reduction to find overall max
for(int s = blockDim.x / 2; s > 0; s >>= 1){
if(tid < s){
max_vals[tid] = fmaxf(max_vals[tid], max_vals[tid + s]);
}
__syncthreads();
}
float max_val = max_vals[0];
__syncthreads();
// Compute sum of exponentials
float thread_sum = 0.0f;
for(int i = tid; i < N; i += blockDim.x){
thread_sum += expf(input[i] - max_val);
}
sum_vals[tid] = thread_sum;
__syncthreads();
// Parallel reduction to find overall sum
for(int s = blockDim.x / 2; s > 0; s >>= 1){
if(tid < s){
sum_vals[tid] += sum_vals[tid + s];
}
__syncthreads();
}
float sum_val = sum_vals[0];
__syncthreads();
// Compute softmax output
for(int i = tid; i < N; i += blockDim.x){
output[i] = expf(input[i] - max_val) / sum_val;
}
}
Problems with the above kernel:
Low occupancy and poor GPU utilization
- Launching a single block activates only one SM, leaving most SMs idle.
- The limited number of active warps reduces the GPU’s ability to hide memory and instruction latency
Potential Register Pressure
- High per-thread register usage combined with a large block size can reduce occupancy and may cause register spilling to local memory, which increases memory traffic and latency.
Reduction is synchronization-heavy
for (s = blockDim.x/2; s > 0; s >>= 1)
__syncthreads();
- Issues:
- log₂(blockDim.x) block-wide barriers
- Barrier latency dominates for small work per thread
- Threads stall frequently
- Multiple full passes over the input
The kernel performs:
- Full traversal for max
- Full traversal for sum
- Full traversal for write That is 3N memory reads and N writes. This increases global memory traffic and puts unnecessary pressure on memory bandwidth.
CUDA Kernel 2: Multiple Kernel launches
To handle the above issues, use Multi-stage reduction (max → exp → sum → normalize).
Reductions will be done at block level.
__device__ void warpReduce(volatile float* sdata, int tid) {
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
__global__ void sum_kernel(const float* input, float* output, int N){
int tid = threadIdx. x;
int gid = threadIdx.x + blockDim.x * blockIdx.x;
extern __shared__ float sOut[];
if(gid < N){
sOut[tid] = input[gid];
}
else{
sOut[tid] = 0.0f;
}
__syncthreads();
for(int i = blockDim.x / 2; i > 32; i >>= 1){
if(tid < i){
sOut[tid] += sOut[tid + i];
}
__syncthreads();
}
if(tid < 32){
warpReduce(sOut,tid);
}
if(tid == 0){
output[blockIdx. x] = sOut[0];
}
}
__global__ void exp_kernel(const float* input, float* output, int N, const float* max_) {
int gid = threadIdx.x + blockDim.x * blockIdx. x;
if(gid < N){
output[gid] = __expf(input[gid] - max_[0]);
}
}
__global__ void normalize_kernel(const float* input, float* output, int N, const float* exp_sum) {
int gid = threadIdx.x + blockDim.x * blockIdx. x;
if(gid < N){
output[gid] = input[gid] / exp_sum[0];
}
}
Problems with the above kernel:
Too many launches
- Max reduction: O(log N)
- Sum reduction: O(log N)
- Plus exp and normalize For large N, this is dozens of launches.
Excessive global memory traffic 4 full reads + 2 full writes of N elements. Still bandwidth-heavy.
Reduction kernels are synchronization-heavy Both reduction kernels use:
for (i >>= 1)
__syncthreads();
- Issues:
- Block-wide barriers at every step
- Shared memory traffic
- Threads idle during sync
CUDA Kernel 3:Online Softmax kernel launches
To tackle launching multiple kernels multiple times, use online softmax implementation with hierarchical (m, d) merging.
- Single-pass statistics per block
- No separate max pass
- No separate exp pass
- No separate sum pass
Each element contributes once to (m, d)
Compared to earlier pipeline:
max → exp → sum → normalize
collapsed 3 global passes → 1 global pass.
For more info into online softmax, you can look [1] in the reference section.
** Will be launching each kernel only once.** After launching block-level sum and max using max_exp_compute_block, will use only one block for kernel max_exp_compute to get global max and exponential sum.
__global__ void max_exp_compute_block(const float* input, float* d_max, float* d_norm, int N){
extern __shared__ float sdata[];
float* max_vals = sdata;
float* norm_vals = &sdata[blockDim.x];
int tid = threadIdx.x;
int gid = threadIdx.x + blockDim.x * blockIdx.x;
float thread_max = -FLT_MAX;
float norm = 0.0;
for (int i = gid; i < N; i += blockDim.x * gridDim.x){
if(thread_max > input[i]){
norm = norm + __expf(input[i] - thread_max);
}
else{
norm = norm * __expf(thread_max - input[i]) + 1;
thread_max = input[i];
}
}
max_vals[tid] = thread_max;
norm_vals[tid] = norm;
__syncthreads();
float max_vals_, norm_vals_;
for(int i = blockDim.x / 2; i > 0; i >>= 1){
if(tid < i){
max_vals_ = fmaxf(max_vals[tid], max_vals[tid + i]);
norm_vals_ = norm_vals[tid] * __expf(max_vals[tid] - max_vals_) + norm_vals[tid + i] * __expf(max_vals[tid + i] - max_vals_);
max_vals[tid] = max_vals_;
norm_vals[tid] = norm_vals_;
}
__syncthreads();
}
float max_val = max_vals[0];
float norm_val = norm_vals[0];
__syncthreads();
if(tid == 0){
d_max[blockIdx.x] = max_val;
d_norm[blockIdx.x] = norm_val;
}
}
__global__ void max_exp_compute(float* d_max, float* d_norm, float* max_g, float* norm_g, int N){
extern __shared__ float sdata[];
float* max_vals = sdata;
float* norm_vals = &sdata[blockDim.x];
int tid = threadIdx.x;
float thread_max = -FLT_MAX;
float norm = 0.0;
for(int i = tid; i < N; i += blockDim.x){
if(thread_max > d_max[i]){
norm = norm + d_norm[i] * __expf(d_max[i] - thread_max);
}
else{
norm = d_norm[i] + norm * __expf(thread_max - d_max[i]);
thread_max = d_max[i];
}
}
max_vals[tid] = thread_max;
norm_vals[tid] = norm;
__syncthreads();
float max_vals_, norm_vals_;
for(int i = blockDim.x / 2; i > 0; i >>= 1){
if(tid < i){
max_vals_ = fmaxf(max_vals[tid], max_vals[tid + i]);
norm_vals_ = norm_vals[tid] * __expf(max_vals[tid] - max_vals_) + norm_vals[tid + i] * __expf(max_vals[tid + i] - max_vals_);
max_vals[tid] = max_vals_;
norm_vals[tid] = norm_vals_;
}
__syncthreads();
}
float max_val = max_vals[0];
float norm_val = norm_vals[0];
__syncthreads();
if(tid == 0){
max_g[0] = max_val;
norm_g[0] = norm_val;
}
}
__global__ void normalize(const float* input, float* output, float *max, float * norm, int N){
int gid = threadIdx.x + blockDim.x * blockIdx.x;
if(gid < N){
output[gid] = __expf(input[gid] - max[0]) / norm[0];
}
}
Further Improvements
- Warp-level reductions
- Reduce register pressure
- Vectorization.
Results
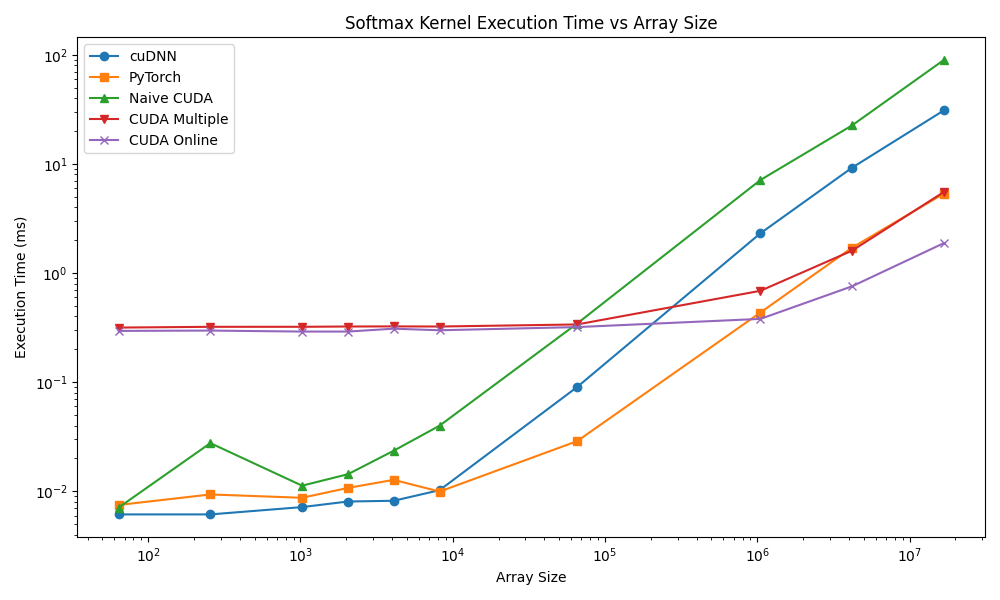
Benchmarking all kernels for kernel execution time(in msec) for an array of 16M elements.
| Kernel | Execution Time(msec.) | Notes |
|---|---|---|
| cuDNN | 30.87 | Uses CUDNN_SOFTMAX_ACCURATE. Numerically stable, launches multiple kernels internally (max, exponentials, sum, normalize) |
| Pytorch | 5.34 | Dispatches to cuDNN or its own stable kernel. Includes temporary buffers and additional abstraction overhead |
| CUDA Kernel 1 | 89.41 | Likely suboptimal: poor memory coalescing, inefficient parallel reduction |
| CUDA Kernel 2 | 5.52 | Optimized for coalesced memory and parallel reductions. Similar performance to PyTorch |
| CUDA Kernel 3 | 1.88 | optimal block/grid configuration, coalesced memory access, in-place computation, minimal overhead |
Observations
- Kernel Execution Time vs. Library Overhead
- cuDNN softmax is slower than custom CUDA kernels because it is designed for generic multi-dimensional tensors and numerical stability.
- Multiple internal kernel launches (max reduction → exponentiation → sum → normalization) increase execution time despite GPU acceleration.
- PyTorch’s softmax closely follows cuDNN in methodology but sometimes leverages simpler dispatch, giving slightly better runtime.
- Memory Access Efficiency
- Custom CUDA kernels (especially Kernel 3) outperform libraries because memory access is perfectly coalesced for a 1D array of 16M elements.
- Kernel 1’s high runtime indicates inefficient memory access or non-optimized thread-block configuration, which severely limits global memory bandwidth utilization.
The following figure shows the performance with respect to array size.
References
[1] Online normalizer calculation for softmax
[2] cuDNN Docs